I have seen several clients who are struggling to decode page allocation failures on Exadata, in this post i will try to explain how to read the backtrace. The following is an anonymized client case where page allocation failures are leading up to a node reboot.
Jan 1 11:58:02 dm01db01 kernel: oracle: page allocation failure. order:1, mode:0x20 Jan 1 11:58:02 dm01db01 kernel: Pid: 80047, comm: oracle Tainted: P 2.6.32-400.11.1.el5uek #1 Jan 1 11:58:02 dm01db01 kernel: Call Trace: Jan 1 11:58:02 dm01db01 kernel: <IRQ> [<ffffffff810ddf74>] __alloc_pages_nodemask+0x524/0x595 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff8110da3f>] kmem_getpages+0x4f/0xf4 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff8110dc3c>] fallback_alloc+0x158/0x1ce Jan 1 11:58:02 dm01db01 kernel: [<ffffffff8110ddd3>] ____cache_alloc_node+0x121/0x134 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff8110e3f3>] kmem_cache_alloc_node_notrace+0x84/0xb9 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff8110e46e>] __kmalloc_node+0x46/0x73 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff813b9aa8>] ? __alloc_skb+0x72/0x13d Jan 1 11:58:02 dm01db01 kernel: [<ffffffff813b9aa8>] __alloc_skb+0x72/0x13d Jan 1 11:58:02 dm01db01 kernel: [<ffffffff813b9bdb>] alloc_skb+0x13/0x15 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff813b9f11>] dev_alloc_skb+0x1b/0x38 Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa02a3722>] ipoib_cm_alloc_rx_skb+0x31/0x1de [ib_ipoib] Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa02a4d04>] ipoib_cm_handle_rx_wc+0x3a1/0x5b8 [ib_ipoib] Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa0198bdc>] ? mlx4_ib_free_srq_wqe+0x27/0x54 [mlx4_ib] Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa01904d4>] ? mlx4_ib_poll_cq+0x620/0x65e [mlx4_ib] Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa029fe97>] ipoib_poll+0x87/0x128 [ib_ipoib] Jan 1 11:58:02 dm01db01 kernel: [<ffffffff813c4b69>] net_rx_action+0xc6/0x1cd Jan 1 11:58:02 dm01db01 kernel: [<ffffffff8105e8cd>] __do_softirq+0xd7/0x19e Jan 1 11:58:02 dm01db01 kernel: [<ffffffff810aefdc>] ? handle_IRQ_event+0x66/0x120 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff81012eec>] call_softirq+0x1c/0x30 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff81014695>] do_softirq+0x46/0x89 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff8105e752>] irq_exit+0x3b/0x7a Jan 1 11:58:02 dm01db01 kernel: [<ffffffff8145bea1>] do_IRQ+0x99/0xb0 Jan 1 11:58:02 dm01db01 kernel: [<ffffffff81012713>] ret_from_intr+0x0/0x11 Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa02bc2df>] ? kcalloc+0x35/0x3d [rds] Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa02bc2df>] ? kcalloc+0x35/0x3d [rds] Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa02bc724>] ? __rds_rdma_map+0x16c/0x32c [rds] Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa02bca09>] ? rds_get_mr+0x42/0x4f [rds] Jan 1 11:58:02 dm01db01 kernel: [<ffffffffa02b67b2>] ? rds_setsockopt+0xae/0x14f [rds] Jan 1 11:58:02 dm01db01 kernel: <EOI> [<ffffffff81458045>] ? _spin_lock+0x21/0x25
Lets take a look at that call trace, in line 1 we see that this regarding the oracle binary that is having the page allocation failures. The way the linux kernel works is that it tries to allocatie pages is in powers of 2, so ‘order:1’ means that linux failed to allocate 2^1 ( 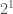
[root@dm0101 ~]# getconf PAGESIZE 4096
so this means we wanted to allocate: 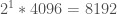
So in this case this system could not allocate 8k of memory, if we walk through the trace we can see where it went wrong. You can see in lines 10,11 en 12 that Linux tries to allocate Socket Kernel Buffers (alloc_skb) and fails. Walking further down the stack we can see it is IP over Infinband that tries to allocate these buffers (ipoib_cm_alloc_rx_skb).
The mode:0x020 line is the GFP (Get Free Pages) flag that is being sent with the request, you can look up what flag it is in gfp.h:
[root@dm0101 ~]# grep 0x20 /usr/src/kernels/`uname -r`/include/linux/gfp.h #define __GFP_HIGH ((__force gfp_t)0x20u) /* Should access emergency pools? */
So if we look further down the messages file we can see the following part:
Jun 14 11:58:02 dm04dbadm02 kernel: Node 0 DMA free:15800kB min:4kB low:4kB high:4kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:15252kB mlocked:0kB dirty:0kB writeback:0kB mapped:0kB shmem:0kB slab_reclaimable:0kB slab_unreclaimable:0kB kernel_stack:0kB pagetables:0kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? yes
As we can see we have only 4kB of low memory left and absolutely no room left in kernel slabs at all. As you can see rds and ip and thus also ipoib are slab allocated pages (you can monitor slabs using slabinfo):
[root@dm0101 ~]# cat /proc/slabinfo | grep "^ip\|rds" rds_ib_frag 23600 23600 8192 1 4 : tunables 8 4 0 : slabdata 23600 23600 0 rds_ib_incoming 23570 23570 8192 1 4 : tunables 8 4 0 : slabdata 23570 23570 0 rds_iw_frag 0 0 40 92 1 : tunables 120 60 8 : slabdata 0 0 0 rds_iw_incoming 0 0 120 32 1 : tunables 120 60 8 : slabdata 0 0 0 rds_connection 18 77 688 11 2 : tunables 54 27 8 : slabdata 7 7 0 ip6_dst_cache 10 24 320 12 1 : tunables 54 27 8 : slabdata 2 2 0 ip6_mrt_cache 0 0 128 30 1 : tunables 120 60 8 : slabdata 0 0 0 ip_mrt_cache 0 0 128 30 1 : tunables 120 60 8 : slabdata 0 0 0 ip_fib_alias 0 0 32 112 1 : tunables 120 60 8 : slabdata 0 0 0 ip_fib_hash 28 106 72 53 1 : tunables 120 60 8 : slabdata 2 2 0 ip_dst_cache 486 530 384 10 1 : tunables 54 27 8 : slabdata 53 53 0 [root@dm0101 ~]#
Furthermore, ipoib uses an MTU size 64k so that is at least an order 4 of slab managed pages.
[root@dm0101 ~]# ifconfig bond0 | grep MTU
UP BROADCAST RUNNING MASTER MULTICAST MTU:65520 Metric:1
With res running on our interconnect this will eventually lead to a node eviction. If rds message can’t be written in the pages then interconnect traffic won’t arrive at this host (remember that infiniband is a lossless fabric).

Hello,
We are facing the same issue on our exadata with 2.6.32-400.11.1.el5uek kernel.
Oracle support doesn’t recognize that as a bug so i just wonder if you found a solution for this ?
Best regards,
Thomas denimal
Hi Thomas, that is because this is not a bug really. It just means that you are using to much memory, for example you have oversized the total amount of SGA memory, leaving no memory for linux and oracle shadow processes. Or for example you have an Oracle process that claiming a lot of PGA memory (e.g. creating a huge memory table using pl/sql). So it is not a bug, it is a result of something else, which in might be a bug or just simply a case of over allocating memory.
but how to setting PGA memory ?
Can you describe in more detail what the output of slabinfo shows in your case?
I was facing a similiar issue with non-exadata rac as in this mos note: 2322410.1. Unfortunately, there were no “/var/log/messages” entries or “page allocation failure” messages, still support requested to lower lo0 mtu size from default (ol7 64k) to 16k.
I could not find any hard evidence that confirms that recommendation based on slabinfo, dmesg, messages in my case.
Regards,
Martin