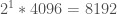In my previous 2 blogposts i explained how to setup a Vagrantfile that deploys 2 virtualbox machines that can be used as a basis for a RAC cluster and how you could use Ansible to deploy RAC on those VM’s. In this post i want to dive a bit deeper into how i setup Ansible and why, keep in mind that this just one way of doing this.
The Github repository containing all the files can be found here
I am not going to go over the contents of the commons role as it probably speaks for itself on what it does. After the common role, we first need to setup networking which we need for interconnects. Because we have added extra network devices and we later on need to make sure that the device we configured as interconnect interface always keeps being the interconnect. Reason for this is that we have configured Virtualbox so that these interfaces are on their own network. To keep the device persistency we configure udev. This will work because in our Vagrantfile we have set the MAC addresses of the interfaces to a fixed value:
- name: Setup udev for network devices
replace: dest=/etc/udev/rules.d/70-persistent-net.rules regexp='ATTR.*{{ item.device }}' replace='ATTR{address}=="{{ item.mac|lower }}", ATTR{type}=="1", KERNEL=="eth*", NAME="{{ item.device }}'
with_items: "{{ network_ether_interfaces }}"
when: network_ether_interfaces is defined
register: udev_net
The array the is being referenced at the with_items line here is a host specific setting so it will take this value from the host_vars/ file. This means that the line above will make an udev rule that is specific for every network interface on the host that ansible is running on.
Ansible uses jinja2 as the format to dynamically format files. We user this format for our network configuration files. With the ansible template command, ansible will read the ethernet.j2 file and the jinja engine will use the template to create the correct file. In case of the action below, the ethernet.j2 will be uploaded as a ifcfg- file and it will do so on every host as long it can find data for that host in host_vars directory:
- name: Create the network configuration for ethernet devices
template: src=ethernet.j2 dest=/etc/sysconfig/network-scripts/ifcfg-{{ item.device }}
with_items: "{{ network_ether_interfaces }}"
when: network_ether_interfaces is defined
register: ether_result
The jinja2 code is quiet simple to read, the ethernet.j2 file looks like this:
# {{ ansible_managed }}
{% if item.bootproto == 'static' %}
DEVICE={{ item.device }}
BOOTPROTO=static
{% if item.address is defined %}
IPADDR={{ item.address }}
{% endif %}
{% if item.onboot is defined %}
ONBOOT={{ item.onboot }}
{% endif %}
{% if item.peerdns is defined %}
PEERDNS={{ item.peerdns }}
{% endif %}
{% if item.defroute is defined %}
DEFROUTE={{ item.defroute }}
{% endif %}
{% if item.netmask is defined %}
NETMASK={{ item.netmask }}
{% endif %}
{% if item.gateway is defined %}
GATEWAY={{ item.gateway }}
{% endif %}
{% if item.mac is defined %}
HWADDR={{ item.mac }}
{% endif %}
{% endif %}
{% if item.bootproto == 'dhcp' %}
DEVICE={{ item.device }}
BOOTPROTO=dhcp
{% endif %}
It is basically divided into to part, the first part tells jinja2 what to do when there is static device configuration and the other one for DHCP enabled devices. Jinja2 will create a line for every item found in the host_vars. The results of this actions are being registered by Ansible with the line “register: ether_result” We are using these results in the next action:
- name: bring up network devices
shell: ifdown {{ item.item.device }}; ifup {{ item.item.device }}
with_items: "{{ ether_result.results }}"
when: ether_result is defined and item.changed
Here we are only restarting those interfaces which are registered in the ether_result action and are changed. A more complex use of ansible is in the template for the hosts file. The hosts file is the basis for DNSMasq which is being used as a simpler alternative for Bind DNS. The template for the hosts file is being created with information from the ansible facts. These facts are being gathered automatically by Ansible as soon as a playbook begins but we have changed things already in this run so right after we have brought up the network interfaces we have gathered our facts again, with these updated facts we can now build our hosts file.
127.0.0.1 localhost
{% for host in groups['all'] %}
{{ hostvars[host]['ansible_eth2']['ipv4']['address'] }} {{ hostvars[host]['ansible_hostname'] }}
{{ hostvars[host]['ansible_eth2']['ipv4']['address'] | regex_replace('(^.*\.).*$', '\\1') }}{{ hostvars[host]['ansible_eth2']['ipv4']['address'].split('.')[3] | int + 10 }} {{ hostvars[host]['ansible_hostname'] }}-vip
{{ hostvars[host]['ansible_eth1']['ipv4']['address'] }} {{ hostvars[host]['ansible_hostname'] }}-priv
{% endfor %}
{% set count = 1 %}
{% for i in range(1,4) %}
{{ hostvars[inventory_hostname]['ansible_eth2']['ipv4']['address'] | regex_replace('(^.*\.).*$', '\\1') }}{{ count | int +250 }} rac-cluster-scan
{% set count = count + 1 %}
{% endfor %}
The for-loop will go through all the facts and get the IP4 address and generates the correct hosts file entry for every node in the cluster. It then takes take the IP4 address and add 10 to the last octet the create the address for the vip interface. The eth1 address i used for the interconnect in our cluster. The last part the the file is a loop the generate 3 additional ip4 addresses based on the address of eth2 and adds 250 to it plus the integer of the loop. These are the our SCAN addresses of our cluster. Now we have the hosts file setup we can install dnsmasq and have DNS ready. We are pinging the interfaces just to make sure they are up, if the ping failes ansible will stop the runbook.
Our network is now setup as we want it to be and we can go on to configure storage. Vagrant already created four shared disks for us which are presented to both virtual machines. We now have to make sure that we have device persistence storage which we can do with both ASMLib and Udev. For both methods there need to be partition, i am using sfdisk as an easy way to create partitions on all 4 disks:
- name: Create disk partitions
shell: echo "0," | sfdisk -q {{item.1}}
with_indexed_items: "{{ device_list.stdout_lines }}"
when: "{{ item.0 }} > 0"
become: true
run_once: true
register: sfdisk_output
The with_indexed_items command gives me an index number which is used to make sure we are not destroying the partitions on /dev/sda where the OS is installed on. Because the OS is installed on the the first disk, we can start sfdisk at index 1. When ansible needs to install asmlib, it then installs the needed RPM’s and uploads and runs a shell script. The reason for this script is that for ASMLib there is some interactivity needed to configure it. This can be solved with regular shell scripting with a here document, as far as i know there is no such thing in Ansible. For Udev we can more or less copy what we did the make our network interfaces persistent.
After we have installed a toolset we can go start with the installation of the Grid Infrastructure. The ASM diskstring and prefix depends on if we have configured it earlier with udev or with asmlib. In order to use the correct valuables i am adding these values to the ansibles facts as custom fact. Depending on which role it finds Ansible well load these values into the facts:
- set_fact: asm_diskstring="/dev/oracleasm/disks" when: "'configure_asmlib' in role_names" - set_fact: asm_diskstring="/dev/ASMDISK*" when: "'configure_udev' in role_names"
Now we can create our SSH keys on both nodes, download the public key back to our Virtual Box host. After we have uploaded the public keys to all the hosts we can add the to our know_hosts using ssh-keyscan.
We upload the Grid Infrastructure zipfiles, extract them and install the cvuqdisk rpm file on all nodes. For the installation of Grid Infrastructure software itself we network_ether_interfaces array to set the client and interconnect interfaces correctly. The response file is made out of a jinja2 template so we can easily customise some settings depending on our needs. Because we are doing a silent install from a response file we need to run the configToolAllCommands which is normally an interactive part when you use the OUI. Finally we create the FRA diskgroup and we can clean up everything we uploaded and now longer need.
The installation of the RDBMS software with Ansible is now very straightforward. It is just a case of adjusting the limits.conf, creating the response file using the jinja2 template and install the software like your regular silent install. The same goes for the actual creation of the database, there are the checks, the response file creation and the database creation itself. For database creation right now i use the response file method, as soon as i have some time i will switch this out for database creation using a template to have more fine-grain control on the created database.
If you take just the Vagrant file and the ansible file and start installing from scratch it will take you a couple of hours (about 3) to download the vagrant box, the software, creating the machines and the provisioning with Ansible.
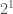 ) pages, so 2 pages in total. We can see how much that is if we lookup the pagesize on Exadata:
) pages, so 2 pages in total. We can see how much that is if we lookup the pagesize on Exadata: